

Hoy en día hablar de bases de datos sin pensar en Tablas y Columnas es muy difícil de imaginar, pues la gran mayoría de nosotros crecimos con bases de datos relacionales, como lo son Oracle, MySQL y SQL Server. Sin embargo, como todas las tecnologías, llega el momento, en que nuevas tecnologías, van desplazando a las anteriores.
Así como las bases de datos relacionales remplazaron a las bases de datos sobre archivos de texto plano, las bases de datos no estructuradas empezando a tomar un protagonismo muy importante, incluso, es posible que, en un futuro no muy lejano, las bases de datos NoSQL empiecen a desplazar a las bases de datos tradicionales.
Hoy en día, han surgido varías propuestas alternativas al modelo SQL, como lo son, Base de datos de Objectos (ObjectDB), Bases de datos de clave-valor (Cassandra), base de datos en tiempo real (Firebase) y bases de datos de documentos (MongoDB), las cuales, a pesar de trabajar de forma diferente, tiene algo en común, y es que todas son Bases de datos NoSQL.
Que es el paradigma NoSQL
Las bases de datos NoSQL tiene como principal característica que guardan información no estructurada, es decir que no existe una tabla y columnas que determinen la forma en que la información deberá ser almacenada. En su lugar, la información puede ser almacenada libremente y la estructura puede variar entre cada registro almacenado.
A pesar de lo que muchas personas piensan, las tecnologías NoSQL no están peleadas con el lenguaje de consultas SQL y muchas de las características que ofrece SQL están siendo implementadas a su manera, con la finalidad de ofrecer una funcionalidad similar.
Las tecnologías NoSQL han tomado una mayor relevancia con la llegada de BigData e Internet de las cosas (IoT), pues cada vez es más común procesar información de un gran número de dispositivos conectados a la nube y toda la información que se está subiendo día a día como documento, videos, conversaciones en redes sociales, fotos, etc. Todos estos ejemplos, que al final del día, son datos no estructurados, que necesitan ser almacenados, procesados y analizados y es allí donde las tecnologías NoSQL están tomando la delantera.
Introducción a MongoDB
MongoDB es la base de datos NoSQL líder del marcado, pues ha demostrado ser lo bastante madura para dar vida a aplicaciones completas. MongoDB nace con la idea de crear aplicaciones agiles, que permita realizar cambios a los modelos de datos si realizar grandes cambios, ya que permite almacenar su información en documentos en formato JSON.
Además, MongoDB es escalable, tiene buen rendimiento y permite alta disponibilidad, escalando de un servidor único a arquitecturas complejas de centros de datos. MongoDB es mucho más rápido de lo que podrías imaginas, pues potencia la computación en memoria.
Uno de los principales retos al trabajar con MongoDB es entender cómo funciona el paradigma NoSQL y abrir la mente para dejar a un lado las tablas y las columnas para pasar un nuevo modelo de datos de Colecciones y documentos, los cuales no son más que estructuras de datos en formato JSON.
Actualmente existe una satanización contra MongoDB y de todas las bases de datos NoSQL en general, ya que los programadores habituales temen salir de su zona de confort y experimentar con nuevos paradigmas. Esta satanización se debe en parte a dos grandes causas: el desconocimiento y la incorrecta implementación. Me explico, el desconocimiento se debe a que los programadores no logran salir del concepto de tablas y columnas, por lo que no encuentra la forma de realizar las operaciones que normalmente hacen con una base de datos tradicional, como es hacer un Join, crear procedimientos almacenados y crear transacciones. Y Finalmente la incorrecta implementación se debe a que los programadores inexpertos o ignorantes utilizan MongoDB para solucionar problemas para los que no fue diseñado, llevando el proyecto directo al fracaso.
Es probable que ellas notado que dije que MongoDB no soporta transacciones, y es verdad, pero eso no significa que MongoDB no sirva, si no que no fue diseñado para aplicaciones que requieren de transacciones y bloque de registro, un que es posible simularlos con un poco de programación.
Bases de datos Relacionales VS MongoDB
Probablemente lo que más nos cueste entender cuando trabajamos con MongoDB es que no utiliza tablas ni columnas, y en su lugar, la información se almacena en objetos completos en formato JSON, a los que llamamos documentos. Un documento se utiliza para representar mucha información contenida en un solo objeto, que, en una base de datos relacional, probablemente guardaríamos en más de una tabla. Un documento MongoDB suele ser un objeto muy grande, que se asemejan a un árbol, y dicho árbol suele tener varios niveles de profundidad, debido a esto, MongoDB requiere de realizar joins para armar toda la información, pues un documento por sí solo, contiene toda la información requerida
Otros de los aspectos importantes de utilizar documentos, es que no existe una estructura rígida, que nos obligue a crear objetos de una determinada estructura, a diferencia una base de datos SQL, en la cual, las columnas determinan la estructura de la información. En MongoDB no existe el concepto de columnas, por lo que los dos siguientes objetos podrían ser guardados sin restricción alguna:
1. {
2. "name": "Juan Perez",
3. "age": 20,
4. "tel": "1234567890"
5. }
|
6. {
7. "name": "Juan Perez",
8. "age": 20,
9. "tels": [
10. "1234567890",
11. "0987654321"
12. ]
13. }
|
Observemos que los dos objetos son relativamente similares, y tiene los mismos campos, sin embargo, uno tiene un campo para el teléfono, mientras que el segundo objeto, tiene una lista de teléfonos. Es evidente que aquí tenemos dos incongruencias con un modelo de bases de datos relacional, el primero, es que tenemos campos diferentes para el teléfono, ya que uno se llama tel y el otro tels. La segunda incongruencia, es que la propiedad tels, del segundo objeto, es en realidad un arreglo, lo cual en una DB relacional, sería una tabla secundaria unida con un Foreign Key.
El segundo objeto se vería de la siguiente manera modelado en una DB relacional:

Como ya nos podemos dar una idea, en un DB relacionar, es necesario tener estructuras definidas y relacionadas entre sí, mientras que en MongoDB, se guardan documentos completos, los cuales contiene en sí mismo todas las relaciones requeridas.
Como funciona MongoDB
Trabajar con MongoDB puede resultar atemorizante en un inicio, pues para realizar las operaciones básicas como insert, update, delete y select, deberemos utilizar un lenguaje basado en JSON.
Antes que nada, puedes crear una base de datos propia en Mongo Atlas, el cual es un servicio de base de datos en la nube y que tiene planes gratuitos de por vida, ideal para realizar tus primeras pruebas sin tener que preocuparte por la instalación. Para ser breves, omitiremos los pasos para crear la base de datos y conectarnos, pues en la misma página te orientarán, por lo que quisiera centrarme únicamente en cómo funciona.
Creando colecciones
Las colecciones son el equivalente a tablas en MongoDB, y permite tener un repositorio en donde guardar los documentos. Para crear un documento se utiliza la instrucción createCollection del objeto db.
![]()
Como resultado, podemos ver la colección en la base de datos

Esta colección no nos solicitará definir una serie de campos ni tipos de datos, porque en realidad podremos guardar el formato que sea.
Insertando datos
Para guardar un documento, tenemos que utilizar el método save de la colección employees, y como parámetro le tenemos que mandar un objeto Javascript, el cual pude tener la estructura que querremos.
Tras ejecutar la operación save, podremos ver el documento directamente sobre la colección:

MongoDB nos crea de forma automática un _id, el cual servirá para que MongoDB pueda identificar como único el registro. Fuera de ese campo, todo el documento permanece igual.
Ahora bien, vamos insertar un nuevo documento con una estructura diferente:

Este nuevo documento tiene una estructura muy diferente, pues estamos agregando toda una nueva sección de proyectos a los que está asignado el empleado, así como una colección de los integrantes del equipo. Si consultamos esta información, podremos ver el siguiente resultado:
Veamos como en una misma colección hemos podido almacenar dos documentos con estructura diferente, incluso, con una estructura anidada.
Actualizando un documento
Para actualizar un documento, solo basta utilizar el método update sobre la colección deseada, y recibe dos parámetros, el primero corresponde al WHERE, es decir, es la condición para determinar que documentos deberá ser actualizados y el segundo parámetros son las actualizaciones a realizar.
En el ejemplo pasado, hemos utilizado el operador $set para agregar el campo website a los empleados con name = Juan Pérez. Como resultado, obtendremos el mismo documento con un nuevo campo:

Consultado un documento
Consultar un documento se realiza mediante el método find, el cual recibe como parámetro, las condiciones de búsqueda, por ejemplo, si queremos buscar un empleado que este en el Proyecto A, deberemos realizar la siguiente consulta:
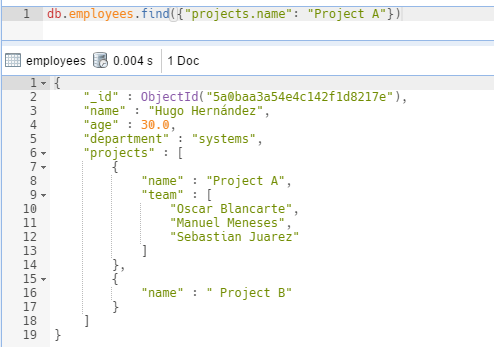
Veamos que es posible acceder a los campos anidados utilizando un punto entre cada anidación. Como resultado hemos obtenido solamente un documento, pues es el único que cumple con la condición.
Borrando documentos
Borrar un documento es todavía más simple, pues solo requerimos indicar la condición de los elementos a eliminar. Veamos un ejemplo:
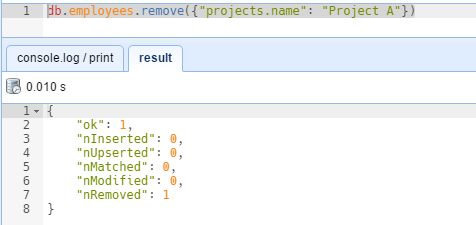
En esta ocasión hemos utilizado el método remove para borrar documentos, dando como resultado, solo un documento eliminado
Conclusiones
Como hemos podido ver, MongoDB es mucho más poderoso y simple de utilizar de lo que hemos podido imaginar. Y si bien, solo hemos visto la punta del iceberg, sí que nos da una idea muy bastante clara de lo que es NoSQL y cómo es que MongoDB funciona. Solo me resta invitarte a que te des una vuelta al sito oficial de MongoDB para que conozcas más.